- 新啟龍運·承蒙厚AI--2024開工季答謝會——泰安站圓滿落幕
- 2024年03月13日 來源:中國網
提要:近日,上海人工智能實驗室(上海AI實驗室)發布新一代高質量大模型預訓練語料“萬卷CC”(WanJuan-CC),首批開源的語料覆蓋過去十年互聯網上的公開內容,包含1千億字符,約400GB的高質量英文數據。
近日,上海人工智能實驗室(上海AI實驗室)發布新一代高質量大模型預訓練語料“萬卷CC”(WanJuan-CC),首批開源的語料覆蓋過去十年互聯網上的公開內容,包含1千億字符(100B token),約400GB的高質量英文數據。作為“大模型語料數據聯盟”今年首發的開源語料,WanJuan-CC將為學界和業界提供大規模、高質量的數據支撐,助力構建更智能可靠的AI大模型。
預訓練數據的質量對大模型整體性能至關重要。當前,CommonCrawl(CC)數據集因其規模大、跨度廣而成為國際主流大模型訓練數據的重要來源。與此同時,其原始數據格式復雜、數據質量低等問題,或將導致模型訓練效率低,甚至可能引發價值觀對齊等方面的隱患。
中國科研人員通過原創的數據清洗技術,從CC數據庫中抽取約1300億份原始數據文檔進行再處理,“萃取”出其中約1.38%的高質量內容,構建成WanJuan-CC語料庫。實驗結果顯示,WanJuanCC具有高文本質量、高信息密度的特點,可滿足當前大模型訓練對大規模高質量語料的需求。
上海AI實驗室發布的書?·浦語2.0(InternLM2)即以WanJuan-CC為關鍵數據作支撐,使訓練效率和語言建模能力大幅提升,綜合性能領先開源社區。
高質量語料驅動,效率性能雙提升
近期,上海AI實驗室發布了新一代大語言模型書?·浦語2.0(InternLM2)。回歸語言建模本質,InternLM2綜合性能達到同量級開源模型的領先水平。模型基座語言建模能力的提升,則得益于預訓練文本質量及信息密度的增強。作為InternLM2的關鍵預訓練語料,WanJuan-CC的文本質量和高信息密度經過了模型實際驗證。在InternLM2的訓練過程中,在僅使用約60%的訓練數據情況下,模型即獲得了與此前使用1T token相同的性能表現,大幅提升訓練效率,并使模型在相同語料規模上取得了更好的性能。
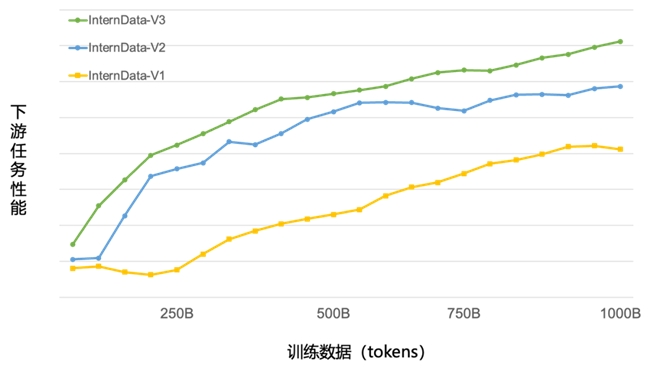
綠色曲線為InternLM2使用WanJuan-cc作為預訓練語料,在不同數據規模上取得的任務性能分布,結果顯示,WanJuan-CC可大幅提升模型訓練效率
研究團隊通過對CC原始數據進行清洗,去除了網頁代碼和重復內容,同時利用分類模型剔除了廣告和質量較差的信息,并通過內容一致性、語法正確性、數據噪聲和信息價值等四個維度,對語言的流暢性進行評估。為驗證數據質量,研究團隊使用WanJuan-CC和RefineWeb(從CommonCrawl中抽取并構建的主流英文預訓練語料)分別重新訓練了參數量1B的模型,并進行評測。結果顯示,由WanJuan-CC作為訓練數據的模型在多項驗證中取得了更優效果。
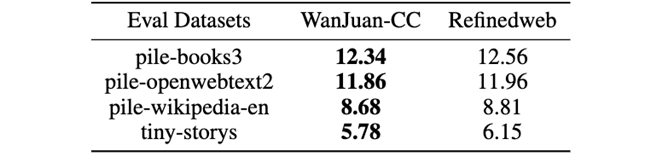
基于WanJuan-CC訓練的1B模型在Pile驗證集評測效果更優,這表明由WanJuan-CC訓練的模型在不同領域和各類知識上擁有更強能力
四重處理, 百里挑一“萃取”高質量數據
為從浩如煙海的CC數據庫中“精選”最可靠的信息,研究團隊搭建了高性能分布式數據處理基礎設施,通過啟發式規則過濾、多層級數據去重、內容安全過濾、數據質量過濾等四個步驟,從原始數據中“萃取”出高質量數據,數據留存率僅為原數據的1.38%。
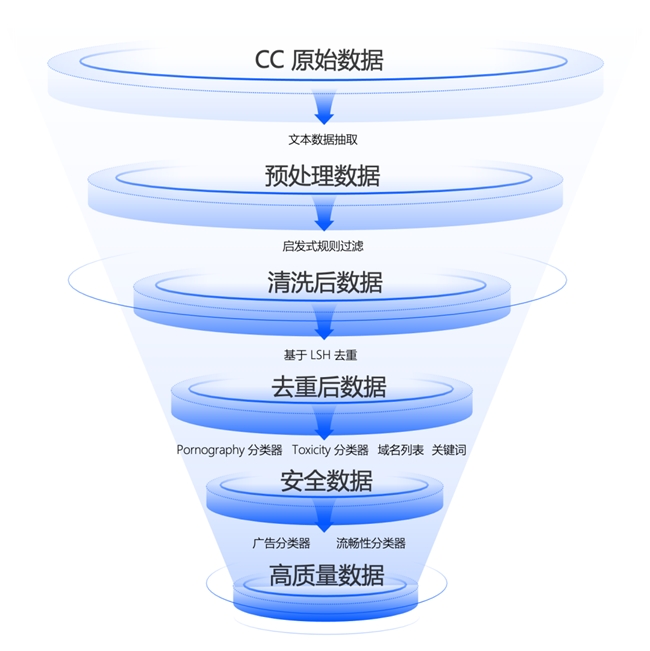
通過原創技術,對CC原始數據進行多階段處理,得到了高信息密度的WanJuan-CC
研究團隊首先從CC中抽取了約1300億份原始數據文檔,然后基于高性能數據處理工作流得到2.2T token(35.8億個文檔)安全數據,最后,根據質量排序精選出1T token(3.6億個文檔)質量最高的數據,構建成WanJuan-CC。如以下柱狀圖所示,在WanJuan-CC構建過程中的每一階段,均進行了大比例的數據去除。對于僅占原CC數據比例2.76%的安全信息,研究人員再次“篩”掉五成低質內容,最終呈現出“百里挑一”的高質量數據。
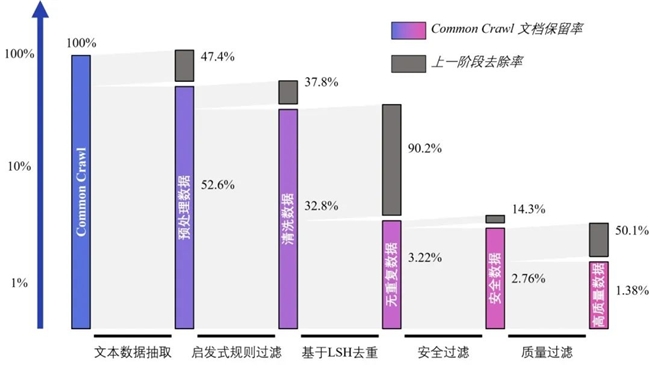
各清洗階段的文檔保留率和去除率(本圖使用對數坐標軸)
數據質量高,模型更可靠
為推動訓練更智能可靠的AI大模型,研究團隊以保障數據安全性為前提,在數據處理的各環節均實施了多項安全加固措施,使WanJuan-CC成為目前開源CC語料中首個在毒性(Toxic)、色情(Porn)和個人隱私三方面同時進行了安全加固的英文語料,因而在價值對齊方面具有更高的可靠性。
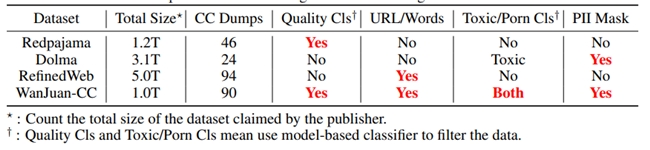
與部分開源CC語料多維度對比,在毒性、色情和個人隱私等方面,WanJuan-CC均進行了安全加固
研究人員分別對WanJuan-CC、Redpajama和Refineweb數據集進行了10萬條數據的抽樣,從毒性、侮辱、恐嚇等7個維度進行評分,以驗證各數據集的信息安全性。結果顯示,WanJuan-CC在各維度上的體現出最高安全性。
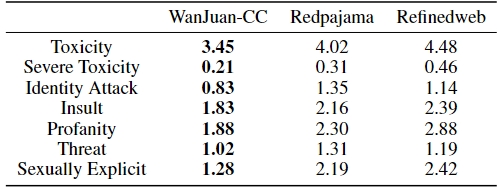
WanJuan-CC與其他開源英文CC語料安全性對比
高質量、多模態、寬領域的數據已成為支持當前人工智能大模型發展的重要基石。WanJuan-CC的主要構建團隊——OpenDataLab致力于建設面向人工智能開發者的超大規模、高質量、多模態開放數據服務平臺,目前已匯聚高質量多模態數據集超6500個,涵蓋大模型研發應用所需的各類語料數據。
大模型語料數據聯盟
由上海人工智能實驗室聯合中央廣播電視總臺、人民網、國家氣象中心、中國科學技術信息研究所、上海報業集團、上海文廣集團等10家單位聯合發起。為應對大模型發展對高質量、大規模、安全可信語料數據資源的需求,保障大模型科研攻關及相關產業生態發展,大模型語料數據聯盟于2023年7月6日世界人工智能大會開幕式上宣布成立,旨在通過鏈接模型訓練、數據供給、學術研究、第三方服務等多方面機構,聯合打造多知識、多模態、標準化的高質量語料數據,探索形成基于貢獻、可持續運行的激勵機制,打造國際化、開放型的大模型語料數據生態圈。





